Create an HPC Cluster
AWS ParallelCluster in a nutshell
A text configuration file you provide to AWS ParallelCluster specifies the defining features of your cluster (e.g., how many nodes it can scale to, what kind of shared storage it uses). AWS ParallelCluster translates those specifications into an AWS CloudFormation template and uses the template to deploy an HPC system based on those settings.
By giving you a clean way to define the infrastructure-as-code for your HPC system, you can easily create numerous clusters tailored to the requirements of individual applications or workloads. For example, you can create one cluster for running workloads that require GPUs and a high-performance parallel file system such as Amazon FSx for Lustre for your machine learning workloads and define another cluster for CPU-optimized workloads with high network bandwidth, such as c5n.24xlarge for your computational fluid dynamics (CFD) jobs.
Another key feature of AWS ParallelCluster is that you can connect to your cluster with NICE DCV to visualize and post-process your data remotely with a virtual desktop. This way you can save time and egress charges by eliminating the need to transfer your data out of AWS!
AWS ParallelCluster provides several commands you can use to manage your cluster such as listing your clusters and their instances, updating a cluster with a new configuration, and shutting down a cluster.
What you will do in this part of the lab
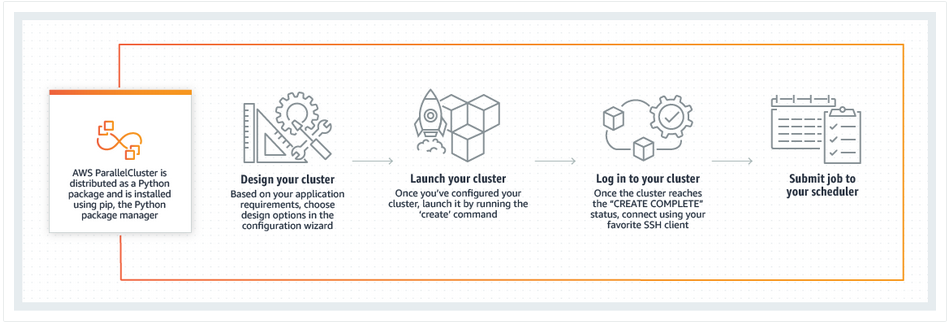
In this lab, you are introduced to AWS ParallelCluster using PCluster Manager. This workshop includes the following steps:
- Connect to PCluster Manager.
- Create your HPC cluster in AWS.
- Connect to your new cluster via the PCluster Manager console.
- Submit a sample job and check what is happening in the background.
Before proceeding to the next stage, let’s review what is AWS ParallelCluster and dive into AWS ParallelCluster API.